Coining Words with a Stenotype
Abstract
The question "does this word sound English?" is harder than it looks. Rule-based phonotactics accumulate exceptions. Existing language models can't embed a word they've never seen. We took a different route: route the question through stenography.
Court reporters have been solving a related problem for decades. The stenotype keyboard encodes English syllable structure so faithfully that it becomes a learned geometric prior for phonological validity. We trained a 623K-parameter transformer to map ARPABET phoneme sequences into steno embedding space, fine-tuned with InfoNCE contrastive learning, and got a scorer that cleanly separates real English phonotactics from garbage, including words that have never existed before.
1. What makes a word sound English
This isn't a philosophical question. It has a technical name: phonotactics, the set of constraints governing which sounds can appear where in a word.
English has real phonotactic structure. The onset cluster ST- is fine (stop, stream, string). TK- doesn't occur. NG- appears as a coda (ring, song) but never as an onset; no English word starts with that sound. SN-, SL-, SP- are all fine. ZB-, GB-, DT- are not.
These aren't arbitrary. They reflect the articulatory and historical pressures that shaped English speech over centuries. Native speakers internalize them without instruction. Ask someone if vlak sounds like it could be an English word and they'll probably say yes. Ask the same about ngum and they'll flinch.
The engineering problem is representing that intuition computationally, not just for words in a dictionary, but for arbitrary phoneme sequences. Invented words. Coinages. Things that have never appeared in text.
Why existing approaches break
Rule-based phonotactics gets you 80% there. You enumerate valid onset clusters, coda clusters, vowel patterns. But edge cases accumulate. Loanwords bend the rules (schmaltzy, vroom). Creative combinations push boundaries in ways that feel valid but no rule explicitly permits. And you have to maintain the list forever. More fundamentally: rules tell you what's in the dictionary. They don't generalize.
Language model embeddings fail for a completely different reason. You can't embed an invented word through BERT or similar. The model has never seen it, so it fragments it into subword tokens that don't reflect the intended phonology. The embedding you get back tells you the word is unfamiliar. You already knew that. The information content is zero.
What you want is something that operates on phoneme sequences, not orthography, not tokens, and scores arbitrary sequences based on learned structure rather than lookup. You want generalization.
2. An aside into stenography
Court reporters write at 200+ words per minute using a machine called a stenotype. Not 200 WPM by typing very fast. 200 WPM by pressing multiple keys simultaneously. One chord. One syllable. One motion.
The stenotype keyboard has 22 keys arranged in three groups:
Left hand (onset): S T K P W H R
Thumbs (vowels): A O * E U
Right hand (coda): F R P B L G T S D Z
The physical layout mirrors English syllable structure directly. Left-hand keys encode onset consonants: the consonant cluster before the vowel. Thumb keys encode the vowel complex. Right-hand keys encode the coda.
To write cat, you press K (left) + A (thumb) + T (right). One simultaneous press. To write strength, you press S + T + R (left) + E (thumb) + NG + T (right). The whole word in one chord.
A chord that doesn't correspond to any English syllable structure can't be pressed, not because the hardware prevents it, but because the layout simply doesn't have a natural mapping for it. NG- as an onset doesn't have a canonical chord because it doesn't occur in English speech. The system would produce a broken, unnatural press sequence, recognizable immediately to any trained stenographer.
This layout was not designed by a linguist writing phonotactic rules. It was refined over decades of professional use by people whose literal job was to represent spoken English fast and without errors. The chord system encodes what's phonologically natural in English because stenographers needed it to work. If a sound combination breaks the system, it breaks because the combination doesn't occur in natural English speech, not because someone wrote a rule saying it shouldn't.
A phoneme sequence that maps cleanly to a valid steno chord is phonotactically plausible. A sequence that produces a broken chord probably isn't.
3. The architecture
We train a transformer encoder to map ARPABET phoneme sequences into steno chord space. The encoder learns the geometry of that space from 44,498 aligned (phoneme sequence, steno stroke) pairs drawn from the CMU Pronouncing Dictionary and the Plover open-source stenotype dictionary.
The input is a phoneme sequence, not the word itself. ARPABET has 39 phonemes (AA, AE, AH, ... ZH). Stress markers are stripped. The vocabulary is [<PAD>, <BOS>, <EOS>] + the 39 phonemes, 42 tokens total.
The model is a 3-layer transformer encoder with 4 attention heads, 128-dimensional embeddings, and a 512-dimensional feedforward layer. Mean-pooling over the attended sequence produces a single 128-dimensional embedding. Two heads sit on top: a stroke predictor (binary classification over the 22 steno keys) and, at inference time, a kNN validity scorer.
Model parameters: 623,510
Small by any measure. The task is structured enough that it doesn't need scale.
Self-attention handles context-dependent phoneme disambiguation. The phoneme cluster /ð ɛr/ is ambiguous in isolation: it could map to there (location) or their (pronoun), which have different steno strokes. In a longer sequence, surrounding phonemes disambiguate. Stenographers do this cognitively in real-time; the attention mechanism encodes it structurally. For invented words, this matters when a user concatenates roots in ways that create phonotactically ambiguous junctions. The model resolves those in context rather than scoring each phoneme independently.
4. Two-phase training
Phase 1: stroke prediction
The first objective is simple: given a phoneme sequence, predict which of the 22 steno keys are active. Multi-label binary cross-entropy against steno targets.
The interesting design choice is soft targets. Homophones like there, their, and they're are phonetically identical but map to different steno strokes (THR, THR*, TH-R). If you commit to one arbitrarily as the training target, you're training against noise. Instead, the target vector is the mean of all valid stroke vectors for that phoneme sequence. The model learns the central tendency of valid steno space rather than arbitrarily committing to one homophone's chord.
Training converges steadily over 20 epochs:
Epoch 01 | Train: 0.3152 | Val: 0.2164
Epoch 05 | Train: 0.1781 | Val: 0.1703
Epoch 10 | Train: 0.1633 | Val: 0.1604
Epoch 15 | Train: 0.1561 | Val: 0.1533
Epoch 20 | Train: 0.1533 | Val: 0.1523
Validation loss plateaus around 0.15. The model extracts most of the available signal in the first dozen epochs. Additional training doesn't help.
Phase 2: InfoNCE fine-tuning
Stroke prediction teaches the model the structure. Fine-tuning tightens the geometry.
With the stroke head frozen, we apply InfoNCE contrastive loss. Real words are positives; synthetic negatives are constructed three ways:
- Shuffled phonemes (40%): take a real word's phoneme sequence, scramble the order. Breaks phonotactic structure while keeping sequence length realistic.
- Random phoneme sampling (40%): pure noise sequences of varying length.
- Known-bad onset clusters (20%): sequences starting with
ZB-,GB-,DT-, orTK-, none of which occur in English. These are the hardest negatives.
The contrastive objective pulls real-word embeddings into coherent neighborhoods without assuming a single cluster. That assumption matters: Germanic and Latinate phoneme patterns are genuinely far apart in phonological space. InfoNCE lets the structure emerge from the data rather than imposing a spherical prior.
Fine-tuning runs for 8 epochs at a lower learning rate (1e-5), with the InfoNCE temperature set to 0.5:
FT Epoch 01 | Loss: 4.3997
FT Epoch 04 | Loss: 4.3856
FT Epoch 08 | Loss: 4.3729
The loss numbers look high because InfoNCE is a ratio over a large similarity matrix. What matters is the trajectory: steady descent, stable convergence.
5. Scoring at inference
The validity score is not a learned parameter. After fine-tuning, we embed the entire validation set (~4,450 words) and cache those normalized embeddings as a reference set. At inference:
- The phoneme sequence is encoded and L2-normalized to a 128-dimensional vector.
- Cosine similarity is computed against all 4,450 reference embeddings.
- The top-50 similarities are averaged.
- The result is passed through a sigmoid.
No learned centroid. The valid region is defined by the actual distribution of real English words in embedding space, multimodal by construction. The scorer is purely geometric, which keeps the encoding decision (the transformer) cleanly separated from the scoring decision (kNN geometry). Both are independently interpretable.
6. What the embedding space looks like
After fine-tuning, we project 2,000 word embeddings through UMAP to see what structure emerged.
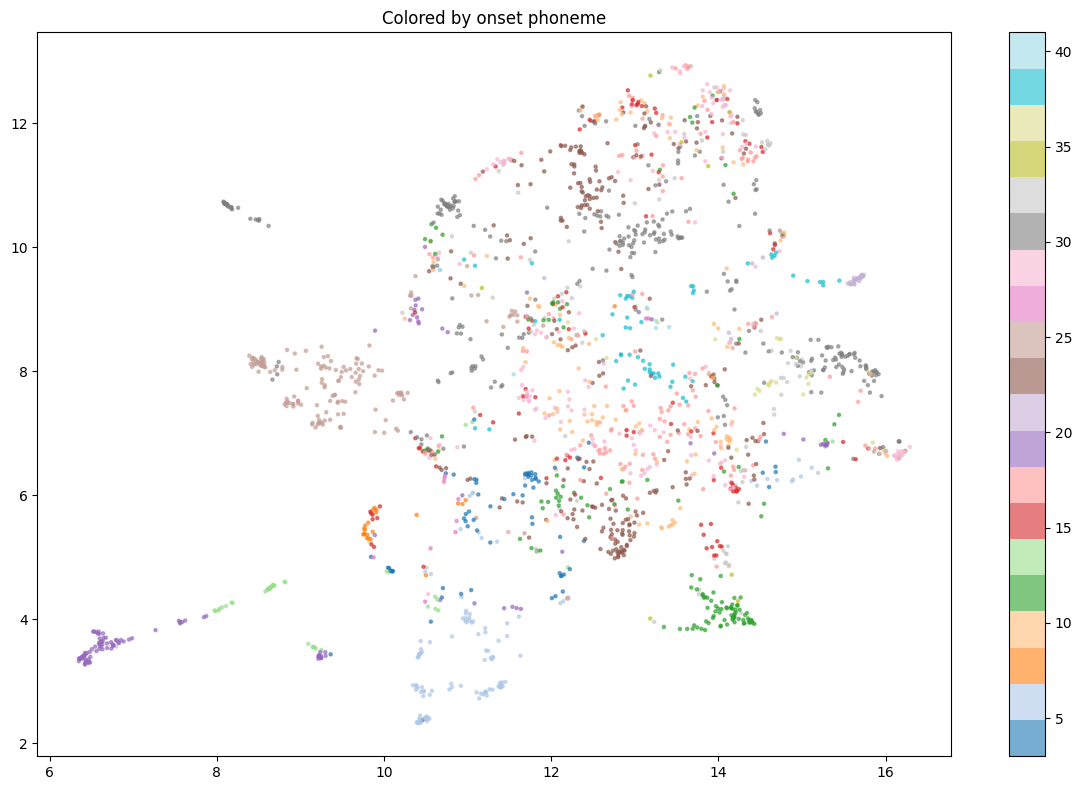
Words cluster by onset phoneme. Words beginning with vowels (IH, EH, AE, AH, AO, OW) occupy a distinct diagonal region, separate from consonantal onsets. Words beginning with S- cluster together. Words beginning with K- cluster separately. The model learned something that looks like phonological neighborhoods.
This wasn't trained in. The model was never told anything about onset phonemes; it was trained to predict steno chords. The steno chord system encodes onset structure implicitly in the left-hand key layout, and the model recovered that structure in its embedding geometry.
The vowel-initial cluster is particularly clean. IH-initial words (interruptions, intrepid, invincible) sit in a tight neighborhood. So do EH-initial words (exponential, entertainment, ecologically). Not because they sound the same, but because the steno left-hand keys for vowel-initial words follow consistent patterns, and the encoder learned to group them.
7. Results on the probe set
After InfoNCE fine-tuning, we tested against a small set of words chosen to probe different cases:
| Input | Phonemes | Score |
|---|---|---|
| frustration (real) | F R AH S T R EY SH AH N | 0.9379 |
| frustation (plausible fake) | F R AH S T EY SH AH N | 0.9397 |
| ngum (bad onset) | NG AH M | 0.1565 |
| shtrik (borderline loanword) | SH T R IH K | 0.4325 |
| vlak (Slavic onset) | V L AE K | 0.9999 |
| glump (valid invented) | G L AH M P | 0.9999 |
| ZBTK garbage | Z B T K AE G | 0.1819 |
| random noise | G Z AH B T IH K D | 0.1267 |
The discrimination is clean. Real English words and plausible coinages score near 1.0. Nonsense scores below 0.2. Borderline cases land in between.
vlak is worth a closer look. VL- is a Slavic onset cluster. It occurs in Czech, Russian, Polish, but not in native English. And yet the model scores it at 0.9999. Is this wrong?
No. VL- is pronounceable by English speakers. It doesn't violate any articulatory constraint. English speakers who encounter vlak will produce it without difficulty. What they won't do is mistake it for a native word, but that's an etymological question, not a phonotactic one. The model is scoring phonetic plausibility, not etymological purity. For a word-coining tool that's the right call: flag sequences that English speakers can't produce, not sequences that merely have foreign origins. Schmuck has German origins. Denim comes from French. Loanwords are how languages grow.
shtrik scores 0.43, borderline. SHT- is a valid transcription of Yiddish influence in English but uncommon enough that it sits at the edge of the valid neighborhood. The model is hedging correctly.
ngum at 0.16 is unambiguous. NG- doesn't occur word-initially in English. No English speaker naturally produces it as an onset. The model learned this from the steno chord structure: there is no left-hand key sequence that produces an NG- onset, because stenographers never needed one.
8. Limitations
The Plover dictionary was built for transcription speed, not linguistic completeness. If a valid English phoneme combination was rare enough that no court reporter needed it at 200 WPM, it may not appear in Plover. The model may score some unusual-but-valid sequences lower than they deserve because those sequences fall outside the training distribution.
The negative sampling is also synthetic. Shuffled phoneme sequences and random phoneme sampling are not the same as real mispronunciations, foreign-language attempts, or the kinds of words people actually invent when trying to coin vocabulary. The validity boundary learned from clean synthetic negatives may not generalize perfectly to messy real-world inputs.
Both are acceptable for a first-version filter. The score is a soft signal, not a hard gate. A low score surfaces a warning; the user can override it.
9. Why the inductive bias works
The steno phonotactic encoder bets that the stenotype keyboard layout is a useful geometric prior for English phonology. That bet pays off because stenography is not arbitrary.
The steno chord system is an empirically-refined representation of English syllable structure, shaped by decades of professional pressure to represent real English speech accurately and at speed. The constraint that made stenography useful to court reporters (that chords must map onto natural English phonological patterns) is exactly what we needed the model to learn.
By training the transformer to predict steno chords from phoneme sequences, we're not just teaching it a transcription task. We're routing learning through a representation that has already encoded phonotactic structure. The model recovers that structure in its embedding geometry, onset clustering, vowel-initial neighborhoods, discrimination between valid and invalid consonant clusters, without any explicit phonological supervision.
The alternative is enumerating rules. Rules require maintenance, break on edge cases, and don't generalize. The steno space generalizes by construction: it scores any phoneme sequence that maps into the embedding space, including ones it has never seen.
Invented words, by definition, have never been seen. The encoder doesn't care.
Code: GitHub